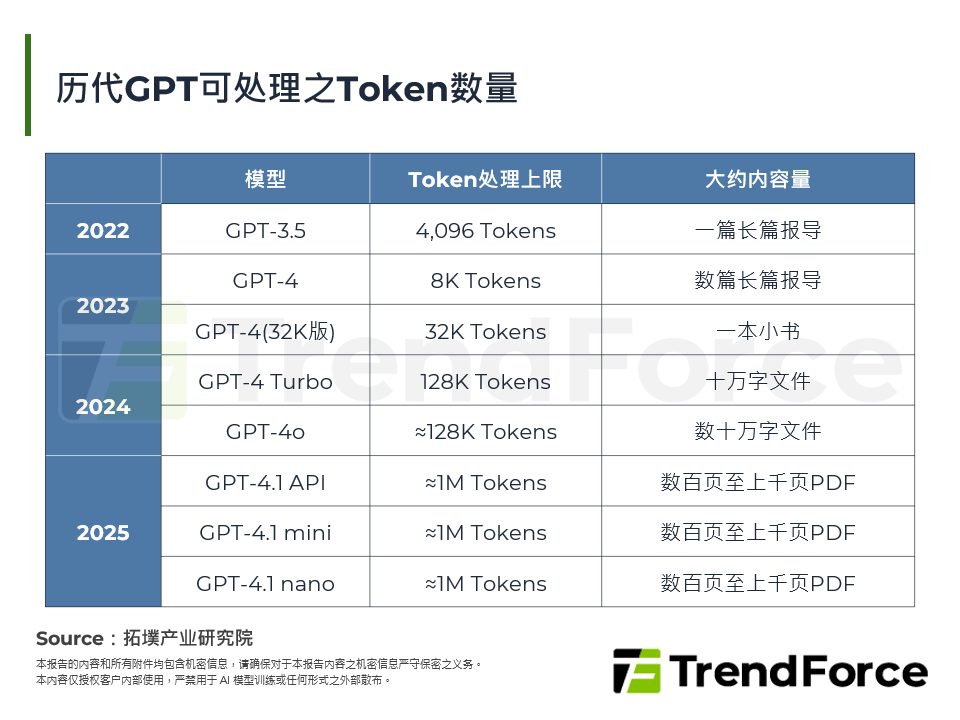
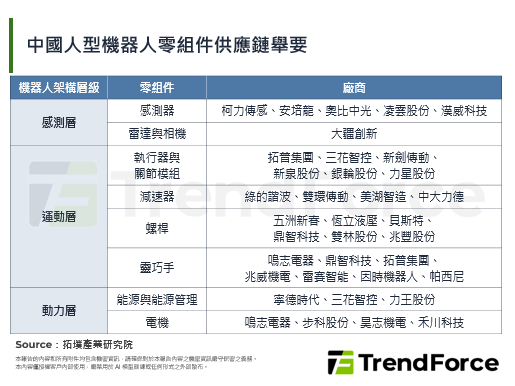
跨越AI记忆体墙:储存阶层的重新分配与HBF剖析
摘要
在AI推理应用中,MoE架构和长文本处理使模型权重与KV Cache对记忆体容量需求大幅提升,让运算瓶颈从算力不足,转向记忆体容量受限。随著海量温数据快速增加,将驱动储存阶层重构,由HBM处理热数据,HBF承载温数据以优化成本效益;然HBF的商业化仍需克服先进封装制程与NAND Flash固有特性的挑战。
一. LLM的发展瓶颈:模型架构的转变影响运算架构
二. 从算力瓶颈到储存阶层的重塑
三. 拓墣观点
图一 MoE特性说明
图二 AI储存阶层厂商布局策略说明
图三 储存阶层的热、温、冷架构说明
图四 「H3」架构说明
表一 HBM与HBF规格对照